Active Template Model
We highly recommend that you render all matplotlib figures inline the Jupyter notebook for the best menpowidgets experience. This can be done by running
%matplotlib inline1. Definition
The aim of deformable image alignment is to find the optimal alignment between a constant template and an input image with rspect to the parameters of a parametric shape model.
Active Template Model (ATM) is such method which is inspired by the Lucas-Kanade Affine Image Alignment and the Active Appearance Model. Note that we invented the name "Active Template Model" for the purpose of the Menpo Project. The term is not established in literature. In this page, we provide a basic mathematical definition of an ATM and all its variations that are implemented within menpofit.
A shape instance of a deformable object is represented as , a vector consisting of landmark points coordinates . An ATM is constructed using a template image that is annotated with landmark points and a set of shapes that are essential for building the hsape model. Specifically, it consists of the following parts:
Shape Model
The shape model is trained as explained in the Point Distributon Model section. The training shapes are first aligned using Generalized Procrustes Analysis and then an orthonormal basis is created using Principal Component Analysis (PCA) which is further augmented with four eigenvectors that represent the similarity transform (scaling, in-plane rotation and translation). This results in where is the orthonormal basis of eigenvectors (including the four similarity components) and is the mean shape vector. An new shape instance can be generated as , where is the vector of shape parameters.Motion Model
The motion model consists of a warp function which is essential for warping the texture related to a shape instance generated with parameters into a commonreference_shape. Thereference_shapeis by default the mean shape , however you can pass in areference_shapeof your preference during construction of the ATM.Template
The provided template image which is annotated with landmarks is further processed by:- First extracting features using the features function defined by
holistic_features, i.e. - Warping the feature-based image into the
reference_shapein order to get - Vectorizing the warped image as where
- First extracting features using the features function defined by
Let's first load a test image and a template image . We'll load two images of the same person (Amanda Peet, actress) from LFPW trainset (see Importing Images for download instructions).
from pathlib import Path
import menpo.io as mio
path_to_lfpw = Path('/path/to/lfpw/trainset/')
image = mio.import_image(path_to_lfpw / 'image_0004.png')
image = image.crop_to_landmarks_proportion(0.5)
template = mio.import_image(path_to_lfpw / 'image_0005.png')
template = template.crop_to_landmarks_proportion(0.5)
The image and template can be visualized as:
%matplotlib inline
import matplotlib.pyplot as plt
plt.subplot(121)
image.view()
plt.gca().set_title('Input Image')
plt.subplot(122)
template.view_landmarks(marker_face_colour='white', marker_edge_colour='black',
marker_size=4)
plt.gca().set_title('Template');

Let's also load the shapes of LFPW trainset that will be used in order to train the PDM:
from menpo.visualize import print_progress
training_shapes = []
for lg in print_progress(mio.import_landmark_files(path_to_lfpw / '*.pts', verbose=True)):
training_shapes.append(lg['all'])
The shapes can be visualized using a widget as:
from menpowidgets import visualize_pointclouds
visualize_pointclouds(training_shapes)
2. Warp Functions
With an abuse of notation, let us define as the feature-based warped vector of an image given its shape instance generated with parameters .
menpofit provides five different ATM versions, which differ on the way that this appearance warping is performed.
Specifically:
HolisticATM
The HolisticATM uses a holistic appearance representation obtained by warping the texture into the reference frame
with a non-linear warp function . Two such warp functions are currently supported:
Piecewise Affine Warp and Thin Plate Spline. The reference frame is the mask of the mean shape's convex hull.
MaskedATM
The MaskedATM uses the same warp logic as the HolsiticATM. The only difference between them is that the
reference frame consists of rectangular mask patches centered around the landmarks instead of the convex hull of the mean shape.
LinearATM
The LinearATM is an experimental variation that utilizes a linear warp function in the motion model, thus a dense statistical shape model which has one shape point per pixel in the reference frame. The advantage is that the linear nature of such warp function makes the computation of its Jacobian trivial.
LinearMaskedATM
Similar to the relation between HolisticATM and MaskedATM, a LinearMaskedATM is exactly the same with a
LinearATM, with the difference that the reference frame is masked.
PatchATM
A PatchATM represents the appearance in a patch-based fashion, i.e. rectangular patches are extracted around the landmark points.
Thus, the warp function simply samples the patches centered around the landmarks of the shape instance generated with parameters .
Let's now create a HolisticATM using IGO features:
from menpofit.atm import HolisticATM
from menpo.feature import igo
atm = HolisticATM(template, training_shapes, group='PTS',
diagonal=180, scales=(0.25, 1.0),
holistic_features=igo, verbose=True)
and visualize it:
atm.view_shape_models_widget()
atm.view_atm_widget()
3. Cost Function and Optimization
Fitting an ATM on a test image involves the optimization of the following cost function with respect to the shape parameters. Note that this cost function is exactly the same as in the case of Lucas-Kanade for Affine Image Alignment. The only difference has to do with the nature of the transform - and thus - that is used in the motion model . Similarly, the cost function is very similar to the one of an Active Appearance Model with the difference that an ATM has no appearance subspace.
The optimization of the ATM deformable image alignment is performed with the Lucas-Kanade gradient descent algorithm. This is the same as in the case of affine image transform, so you can refer to the Lucas-Kanade chapter for more information. We currently support Inverse-Compositional and Forward-Compositional optimization.
Let's now create a Fitter using the ATM we created, as:
from menpofit.atm import LucasKanadeATMFitter, InverseCompositional
fitter = LucasKanadeATMFitter(atm,
lk_algorithm_cls=InverseCompositional, n_shape=[5, 15])
Information about the fitter can be retrieved as:
print(fitter)
which returns
Holistic Active Template Model
- Images warped with DifferentiablePiecewiseAffine transform
- Images scaled to diagonal: 180.00
- Scales: [0.25, 1.0]
- Scale 0.25
- Holistic feature: igo
- Template shape: (38, 38)
- Shape model class: OrthoPDM
- 132 shape components
- 4 similarity transform parameters
- Scale 1.0
- Holistic feature: igo
- Template shape: (133, 134)
- Shape model class: OrthoPDM
- 132 shape components
- 4 similarity transform parameters
Inverse Compositional Algorithm
- Scales: [0.25, 1.0]
- Scale 0.25
- 3 active shape components
- 4 similarity transform components
- Scale 1.0
- 20 active shape components
- 4 similarity transform components
Let's know fit the ATM on the image we loaded in the beggining.
We will use the DLib face detector from menpodetect, in order to acquire an initial bounding box, as:
from menpodetect import load_dlib_frontal_face_detector
# Load detector
detect = load_dlib_frontal_face_detector()
# Detect
bboxes = detect(image)
print("{} detected faces.".format(len(bboxes)))
# View
if len(bboxes) > 0:
image.view_landmarks(group='dlib_0', line_colour='white',
render_markers=False, line_width=3);

and fit the ATM as:
# initial bbox
initial_bbox = bboxes[0]
# fit image
result = fitter.fit_from_bb(image, initial_bbox, max_iters=20,
gt_shape=image.landmarks['PTS'].lms)
# print result
print(result)
which prints
Fitting result of 68 landmark points.
Initial error: 0.0877
Final error: 0.0196
The result can be visualized as:
result.view(render_initial_shape=True)
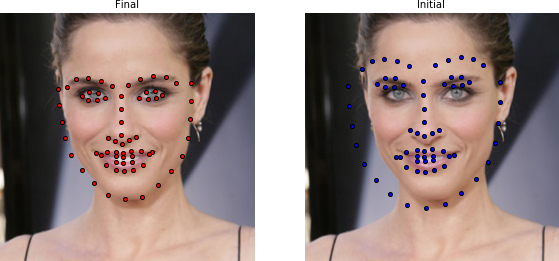
or using a widget as:
result.view_widget()
Remember that the shape per iteration can be retrieved as
result.shapes
Similarly, the shape and appearance parameters per iteration can be obtained as:
print(result.shape_parameters.shape)
print(result.appearance_parameters.shape)
4. References
[1] I. Matthews, and S. Baker. "Active Appearance Models Revisited", International Journal of Computer Vision, vol. 60, no. 2, pp. 135-164, 2004.