Active Appearance Model
- Definition
- Warp Functions
- Cost Function and Optimization
3.1. Lucas-Kanade Optimization
3.2. Supervised Descent Optimization - Fitting Example
- References
- API Documentation
We highly recommend that you render all matplotlib figures inline the Jupyter notebook for the best menpowidgets experience. This can be done by running
%matplotlib inline1. Definition
Active Appearance Model (AAM) is a statistical deformable model of the shape and appearance of a deformable object class.
It is a generative model which during fitting aims to recover a parametric description of a certain object through optimization.
In this page, we provide a basic mathematical definition of an AAM and all its variations that are implemented within menpofit.
For a more in-depth explanation of AAM, please refer to the relevant literature in References and especially [1].
A shape instance of a deformable object is represented as , a vector consisting of landmark points coordinates . An AAM [6, 8] is trained using a set of images that are annotated with a set of landmarks and it consists of the following parts:
- Shape Model
The shape model is trained as explained in the Point Distributon Model section. The training shapes are first aligned using Generalized Procrustes Analysis and then an orthonormal basis is created using Principal Component Analysis (PCA) which is further augmented with four eigenvectors that represent the similarity transform (scaling, in-plane rotation and translation). This results in where is the orthonormal basis of eigenvectors (including the four similarity components) and is the mean shape vector. An new shape instance can be generated as , where is the vector of shape parameters.
- Motion Model
The motion model consists of a warp function which is essential for warping the texture related to a shape instance generated with parameters into a commonreference_shape. Thereference_shapeis by default the mean shape , however you can pass in areference_shapeof your preference during construction of the AAM.
Appearance Model
The appearance model is trained by:- First extracting features from all the training images using the features function defined by
holistic_features, i.e. , - Warping the feature-based images into the
reference_shapein order to get , - Vectorizing the warped images as , where
- Applying PCA on the acquired vectors which results in where is the orthonormal basis of eigenvectors and is the mean appearance vector.
A new appearance instance can be generated as , where is the vector of appearance parameters.
- First extracting features from all the training images using the features function defined by
Before continuing, let's load the trainset of LFPW (see Importing Images for download instructions) as
import menpo.io as mio
from menpo.visualize import print_progress
from menpo.landmark import labeller, face_ibug_68_to_face_ibug_68_trimesh
path_to_images = '/path/to/lfpw/trainset/'
training_images = []
for img in print_progress(mio.import_images(path_to_images, verbose=True)):
# convert to greyscale
if img.n_channels == 3:
img = img.as_greyscale()
# crop to landmarks bounding box with an extra 20% padding
img = img.crop_to_landmarks_proportion(0.2)
# rescale image if its diagonal is bigger than 400 pixels
d = img.diagonal()
if d > 400:
img = img.rescale(400.0 / d)
# define a TriMesh which will be useful for Piecewise Affine Warp of HolisticAAM
labeller(img, 'PTS', face_ibug_68_to_face_ibug_68_trimesh)
# append to list
training_images.append(img)
Note that we labeled the images using face_ibug_68_to_face_ibug_68_trimesh, in order to
get a manually defined TriMesh for the Piecewise Affine Warp. However, this is not necessary and it only applies
for HolisticAAM. We can visualize the images using an interactive widget as:
%matplotlib inline
from menpowidgets import visualize_images
visualize_images(training_images)
2. Warp Functions
With an abuse of notation, let us define as the feature-based warped vector of an image given its shape instance generated with parameters .
menpofit provides five different AAM versions, which differ on the way that this appearance warping is performed.
Specifically:
HolisticAAM
The HolisticAAM uses a holistic appearance representation obtained by warping the texture into the reference frame
with a non-linear warp function . Two such warp functions are currently supported:
Piecewise Affine Warp and Thin Plate Spline. The reference frame is the mask of the mean shape's convex hull.
Let's create a HolisticAAM using Dense SIFT features:
from menpofit.aam import HolisticAAM
from menpo.feature import fast_dsift
aam = HolisticAAM(training_images, group='face_ibug_68_trimesh', diagonal=150,
scales=(0.5, 1.0), holistic_features=fast_dsift, verbose=True,
max_shape_components=20, max_appearance_components=150)
and visualize it:
aam.view_shape_models_widget()
aam.view_appearance_models_widget()
aam.view_aam_widget()
MaskedAAM
The MaskedAAM uses the same warp logic as the HolsiticAAM. The only difference between them is that the
reference frame consists of rectangular mask patches centered around the landmarks instead of the convex hull of the mean shape.
LinearAAM
The LinearAAM is an experimental variation that utilizes a linear warp function in the motion model, thus a dense statistical shape model which has one shape point per pixel in the reference frame. The advantage is that the linear nature of such warp function makes the computation of its Jacobian trivial.
LinearMaskedAAM
Similar to the relation between HolisticAAM and MaskedAAM, a LinearMaskedAAM is exactly the same with a
LinearAAM, with the difference that the reference frame is masked.
PatchAAM
A PatchAAM represents the appearance in a patch-based fashion, i.e. rectangular patches are extracted around the landmark points.
Thus, the warp function simply samples the patches centered around the landmarks of the shape instance generated with parameters .
Let's create a PatchAAM using Dense SIFT features:
from menpofit.aam import PatchAAM
from menpo.feature import fast_dsift
patch_aam = PatchAAM(training_images, group='PTS', patch_shape=[(15, 15), (23, 23)],
diagonal=150, scales=(0.5, 1.0), holistic_features=fast_dsift,
max_shape_components=20, max_appearance_components=150,
verbose=True)
and visualize it:
patch_aam.view_appearance_models_widget()
patch_aam.view_aam_widget()
3. Cost Function and Optimization
Fitting an AAM on a test image involves the optimization of the following cost function with respect to the shape and appearance parameters. Note that this cost function is very similar to the one of Lucas-Kanade for Affine Image Alignment and Active Template Model for Deformabe Image Alignment. The only difference has to do with the fact that an AAM aims to align the test image with a linear appearance model.
This optimization can be solved by two approaches:
3.1. Lucas-Kanade Optimization
The Lucas-Kanade optimization belongs to the family of gradient-descent algorithms. In general, the existing gradient descent optimization techniques are categorized as: (1) forward or inverse depending on the direction of the motion parameters estimation and (2) additive or compositional depending on the way the motion parameters are updated. menpofit currently provides the Forward-Compositional and Inverse-Compositional version of five different algorithms. All these algorithms are iterative and the shape parameters are updated at each iteration in a compositional manner as
Below we briefly present the Inverse-Compositional of each one of them, however the Forward-Compositional can be derived in a similar fashion.
- Project-Out
The Project-Out Inverse-Compositional algorithm [8] decouples shape and appearance by solving the AAM optimization problem in a subspace orthogonal to the appearance variation. This is achieved by "projecting-out" the appearance variation, thus working on the orthogonal complement of the appearance subspace . The cost function has the form By taking the first-order Taylor expansion on the part of the model over we get . Thus, the incermental update of the shape parameters is computed as where is the Gauss-Newton approximation of the Hessian matrix and is the projected-out Jacobian. The appearance parameters can be retrieved at the end of the iterative optimization as in order to reconstruct the appearance. Note that the Jacobian, Hessian and its inverse are constant and can be pre-computed, which makes the Project Out Inverse Compositional fast with computational cost .
- Simultaneous
In the Simultaneous Inverse-Compositional algorithm [7], we aim to optimize simultaneously for the shape and the appearance parameters. The cost function has the form where are the appearance eigenvectors, i.e. . Note that the appearance parameters are updated in an additive manner, i.e. . We denote by the vector of concatenated parameters increments with length . The linearization of the model part around consists of two parts: the mean appearance vector approximation and the linearized basis . Then the final solution at each iteration is where the Hessian matrix is and the Jacobian is given by with . The Jacobian of the mean appearance vector and the eigenvectors are constant and can be precomputed. However, the total Jacobian and hence the Hessian matrix depend on the current estimate of the appearance parameters , thus they need to be computed at every iteration. The computational complexity is .
- Alternating
In the Alternating Inverse-Compositional algorithm [9, 12, 13, 2], the cost function has the same form as in the case of Simultaneous Inverse-Compositional, i.e. where are the appearance eigenvectors, i.e. . The linearization also has the exact same formulation. The only difference is that we optimize with respect to and in an alternated manner instead of simultaneously. Specifically, assuming that we have the current estimation of , the appearance parameters incremental is computed as Then, given the current estimate of , the shape parameters increment is comptuted as Note that the appearance parameters vector is updated in an additive fashion, i.e. . As in the Simultaneous case, the Jacobian is given by and the Hessian matrix is . The computational complexity is .
- Modified Alternating
The Modified Alternating Inverse-Compositional algorithm is very similar to the Alternating case. The only difference is that we do not introduce an incremental update on the appearance parameters. Instead, the current appearance parameters vector is computed by projecting the input image with shape parameters into the appearance subspace. Specifically, the shape parameters increment given the current estimate of the appearance parameters is given by Then, the appearance parameters for the next iteration are obtained by projecting into the appearance model as The Jacobian and Hessian are the same as in the Alternating case, i.e. and . The computational complexity is which is very similar to the Alternating.
- Wiberg
The Wiberg Inverse-Compositional algorithm [9, 13, 11] is a very efficient version of alternating optimization. It involves solving two different problems in an alternating manner, one for the shape and one for the appearance parameters increments where is the "project-out" operator. Given the current estimate of , the shape parameters increment estimated by solving the first optimization problem as where is the projected-out Jacobian with and being the Gauss-Newton approximation of the Hessian. Given the current estimate of , the appearance parameters increment is computed by solving the second optimization problem as The computational cost of Wiberg optimization is , as shown in [13]. Note that Wiberg and Simultaneous have been shown to be theoretically equivalent and that the only difference is their computational costs. That is the Simultaneous Inverse-Compositional algorithm requires to invert the Hessian of the concatenated shape and appearance parameters (). However, using the fact that and solving first for the appearance parameter increments, it has been shown that the complexity of Simultaneous can be reduced dramatically and that Simultaneous is equivalent to Wiberg algorithm [13] (similar results can be shown by using the Schur’s complement of the Hessian of shape and appearance parameters).
Let's now create a Lucas-Kanade Fitter for the patch-based AAM that we trained above using the Wiberg Inverse-Compositional algorithm, as
from menpofit.aam import LucasKanadeAAMFitter, WibergInverseCompositional
fitter = LucasKanadeAAMFitter(patch_aam, lk_algorithm_cls=WibergInverseCompositional,
n_shape=[5, 20], n_appearance=[30, 150])
Remember that you can always retrieve information about any trained model by:
print(fitter)
3.2. Supervised Descent Optimization
The AAM cost function can also be optimized using cascaded regression, which in literature is commonly referred to as Supervised Descent Optimization, a name given by [15]. Specifically, the aim is to learn a regression function that regresses from the object’s features based on the appearance model to the parameters of the statistical shape model. Although the history behind using linear regression in order to learn descent directions spans back many years when AAMs were first introduced [6], the research community turned towards alternative approaches due to the lack of sufficient data for training accurate regression functions. Nevertheless, over the last few years, regression-based techniques have prevailed in the field [14, 15] thanks to the wealth of readily available annotated data and powerful handcrafted features.
Regression Features
Let's define a feature extraction function given an image and a shape parameters vector as
which returns an feature vector based on the warped image . Note that includes the appearance features extraction (e.g. SIFT), as defined in the Warp Functions paragraph. menpofit includes three Supervised Descent Optimization variants based on these regression features. Specifically:
| Variant | Features |
|---|---|
| Appearance Weights | |
| Project Out | |
| Mean Template |
Training
Assume that we have a set of training images and their corresponding annotated shapes . By projecting each ground-truth shape onto the shape basis , we compute the ground-truth shape parameters . We generate a set of perturbed shape parameters , which are sampled from a distribution that models the statistics of the detector employed for initialization. By defining to be a set of shape parameter increments, a Supervised Descent algorithm aims to learn a cascade of optimal linear regressors at each level
where is the number of shape components of the AAM and is the features dimensionality, by minimizing
with respect to .
The training procedure includes the following steps:
- Shape Parameters Increments: Given the set of vectors , we formulate the set of shape parameters increments vectors and concatenate them in an matrix .
- Residuals: The next step is to compute the appearance feature vectors from the perturbed shape locations . These vectors are then concatenated in a single matrix as .
- Regression Descent Directions: By using the previously above defined matrices, the training cost function takes the form . The closed-form solution of the above least-squares problem is .
- Shape Parameters Update: The final step is to generate the new estimates of the shape parameters per training image as , and . After obtaining , steps 1-4 are repeated for the next cascade level.
Fitting
During fitting, we obtain the current shape parameters increment using the regression matrix of level as
and use it in order to update the shape parameters for the next level in an additive way
The above procedure is repeated for each cascade level, i.e. .
4. Fitting Example
Let's load a test image from LFPW testset and convert it to grayscale
from pathlib import Path
import menpo.io as mio
path_to_lfpw = Path('/path/to/lfpw/testset/')
image = mio.import_image(path_to_lfpw / 'image_0018.png')
image = image.as_greyscale()
Let's also load a pre-trained face detector from menpodetect and try to find the face's bounding box in order to initialize the AAM fitting
from menpodetect import load_dlib_frontal_face_detector
# Load detector
detect = load_dlib_frontal_face_detector()
# Detect
bboxes = detect(image)
print("{} detected faces.".format(len(bboxes)))
# View
if len(bboxes) > 0:
image.view_landmarks(group='dlib_0', line_colour='red',
render_markers=False, line_width=4);

The fitting can be executed as
# initial bbox
initial_bbox = bboxes[0]
# fit image
result = fitter.fit_from_bb(image, initial_bbox, max_iters=[15, 5],
gt_shape=image.landmarks['PTS'].lms)
# print result
print(result)
which prints
Fitting result of 68 landmark points.
Initial error: 0.1689
Final error: 0.0212
The fitting result can be visualized as
result.view(render_initial_shape=True)

and the fitting iterations as
result.view_iterations()

Also, you can plot the fitting error per iteration as
result.plot_errors()
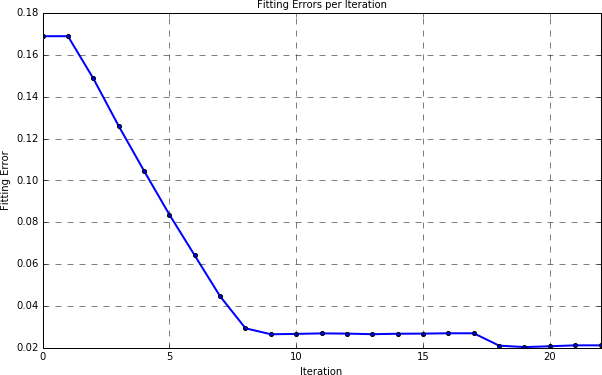
and of course the fitting result widget can be called as
result.view_widget()
Let's try an image with a more challenging head pose
import matplotlib.pyplot as plt
# Load and convert to grayscale
image = mio.import_image(path_to_lfpw / 'image_0152.png')
image = image.as_greyscale()
# Detect face
bboxes = detect(image)
# Crop the image for better visualization of the result
image = image.crop_to_landmarks_proportion(0.3, group='dlib_0')
bboxes[0] = image.landmarks['dlib_0'].lms
if len(bboxes) > 0:
# Fit AAM
result = fitter.fit_from_bb(image, bboxes[0], max_iters=[15, 5],
gt_shape=image.landmarks['PTS'].lms)
print(result)
# Visualize
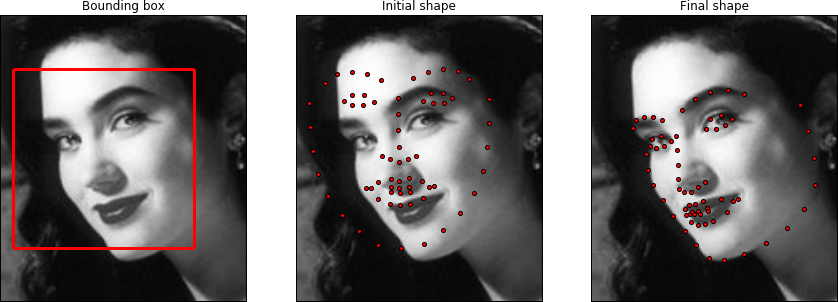
plt.subplot(131);
image.view()
bboxes[0].view(line_width=3, render_markers=False)
plt.gca().set_title('Bounding box')
plt.subplot(132)
image.view()
result.initial_shape.view(marker_size=4)
plt.gca().set_title('Initial shape')
plt.subplot(133)
image.view()
result.final_shape.view(marker_size=4, figure_size=(15, 13))
plt.gca().set_title('Final shape')
and trigger the widget
result.view_widget()
Remember that the shape per iteration can be retrieved as
result.shapes
Similarly, the shape and appearance parameters per iteration can be obtained as:
print(result.shape_parameters.shape)
print(result.appearance_parameters.shape)
5. References
[1] J. Alabort-i-Medina, and S. Zafeiriou. "A Unified Framework for Compositional Fitting of Active Appearance Models", arXiv:1601.00199.
[2] J. Alabort-i-Medina, and S. Zafeiriou. "Bayesian Active Appearance Models", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[3] E. Antonakos, J. Alabort-i-Medina, G. Tzimiropoulos, and S. Zafeiriou. "Feature-based Lucas-Kanade and Active Appearance Models", IEEE Transactions on Image Processing, vol. 24, no. 9, pp. 2617-2632, 2015.
[4] E. Antonakos, J. Alabort-i-Medina, G. Tzimiropoulos, and S. Zafeiriou. "HOG Active Appearance Models", IEEE International Conference on Image Processing (ICIP), 2014.
[5] S. Baker, and I. Matthews. "Lucas-Kanade 20 years on: A unifying framework", International Journal of Computer Vision, vol. 56, no. 3, pp. 221-255, 2004.
[6] T.F. Cootes, G.J. Edwards, and C.J. Taylor. "Active Appearance Models", IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 23, no. 6, pp. 681–685, 2001.
[7] R. Gross, I. Matthews, and S. Baker. "Generic vs. person specific Active Appearance Models", Image and Vision Computing, vol. 23, no. 12, pp. 1080-1093, 2005.
[8] I. Matthews, and S. Baker. "Active Appearance Models Revisited", International Journal of Computer Vision, vol. 60, no. 2, pp. 135-164, 2004.
[9] G. Papandreou, and P. Maragos. "Adaptive and constrained algorithms for inverse compositional active appearance model fitting", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2008.
[10] G. Tzimiropoulos, J. Alabort-i-Medina, S. Zafeiriou, and M. Pantic. "Active Orientation Models for Face Alignment in-the-wild", IEEE Transactions on Information Forensics and Security, Special Issue on Facial Biometrics in-the-wild, vol. 9, no. 12, pp. 2024-2034, 2014.
[11] G. Tzimiropoulos, and M. Pantic. "Gauss-Newton Deformable Part Models for Face Alignment In-the-Wild", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[12] G. Tzimiropoulos, J. Alabort-i-Medina, S. Zafeiriou, and M. Pantic. "Generic Active Appearance Models Revisited", Asian Conference on Computer Vision, Springer, 2012.
[13] G. Tzimiropoulos, M. Pantic. "Optimization problems for fast AAM fitting in-the-wild", IEEE International Conference on Computer Vision (ICCV), 2013.
[14] G. Tzimiropoulos. "Project-Out Cascaded Regression with an application to Face Alignment", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[15] X. Xiong, and F. De la Torre. "Supervised descent method and its applications to face alignment", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013.